先日、NTT Tech Conferenceに参加しました。そこで、DevOpsのセッションを聞いて色々と思うところがあったので、手持ちの資料から抜粋して色々と書いてみます。
大本の資料は、2013から2015年にかけて、九州工業大学でM1の学生向けに講演した内容になります。
今思えば、「ベンチャー企業におけるDevOpsについて話してほしい」という依頼に対して、「DevOpsと社内政治」について話してしまったので、本当に申し訳ないと思ってる。
まあ、ツールはいくらでも移り変わるが根源の思想はどこまで行っても変わらんので、思想教育だけしておけばいいかなというのはある。
さて、昨今DevOpsが話題で、「DevOpsをやってみたいので、どのツールを使ったらいいか教えてくれ」みたいな残念な会話をチラホラ耳にします(と、NTTの中の人が言ってしました)。
この手の人々が残念なのは、DevOps云々の前に、なぜDevとOpsが対立するのか、というあたりまえの前提を理解していないことにあります。
そのため、本稿ではなぜDevとOpsが対立するのか、というところから、DevOpsとは何か、を説明できれば幸いです。
そして例によって、この文章はポエムです。
DevOpsの初出
初出は2009年、オライリー主催のVelocity 2009
Flickrのエンジニアによって「開発と運用が協力することで、1日に10回以上のペースでリリース可能になる」と発表されたのが大本です。
上記資料の解説については、下記資料が詳しいのでそちらも参考に。
ここから、DevとOpsが協力すればより効率的になる=DevOps、という言葉が生まれました。
当時は大企業においてはDevとOpsが分かれていることが当たり前だったのです。そして、大企業における当たり前が、当たり前ではないことに気付き始め、DevOpsを実現するためのツールができ始めたころでもあります。
ではなぜ、大企業ではDevとOpsが分かれているのが当たり前だったのでしょうか?
ハードウェアの時代
その昔、産業の主役はハードウェアでした。
そのため、多くの企業はハードウェアを作ることに対して最適化が行われました。
ハードウェアには研究開発、製造、運用サポートといった大きな区分けが存在します。そして、それぞれの仕事において要求する人材レベルは異なります。
加えて、大量生産された製品の運用サポート(設置作業員、サポートセンタ)には、大量の人員が必要になってきます。
したがって、組織を研究開発、製造、運用サポートに切り分けることは、当時は合理的でした。
つまり、少数精鋭高学歴の研究開発、高等教育を受けた製造オペレータ、大量の低スキルの運用人員、という構成にならざるを得ませんでした。
また、ハードウェアの新機種が出るのは、半年に一度程度のスパンでした。
そしてハードウェアは一度製造してしまったら直しようがないため、不具合があれば運用マニュアルで回避することが求められました。
「運用でカバー」はハードウェアの時代には当たり前で、仕方がないものでした。
この時代の会社構造がある種の常識化してしまっており、それが産業構造が変わった現代にも適応されてしまっています。これが諸所の問題を引き起こしています。
ソフトウェアの時代
ハードウェアの時代の成功は、開発と運用を別組織にするという常識を作り上げました。そしてそれはソフトウェア産業が台頭してきた今日でも続いています。
開発と運用は組織が異なるため当然のように業績評価指標が異なってきます。
開発では、新しい機能をリリースすること、が業績評価になり、
運用では、システムを安定稼働すること、が業績評価になります。
ソフトウェアビジネスの特徴として「新しい機能には必ずバグがある」という問題があります。しかしソフトウェアのアップデートが半年に一回程度であれば、ハードウェアの時代とそう変わらないため、大きな問題はありませんでした。
ハードウェアの時代に成功した組織構造は、ソフトウェアの時代になっても、ある一定までは大丈夫だったのです。
しかし、時代がインターネットだ、Web2.0だ、となってくると話は変わってきます。ウェブサービスは毎日がアップデートなので、毎日がバグということになります。ここにきて、ハードウェアに最適化された組織が火を噴き始めました。
毎日がアップデートでは、運用マニュアルの更改では追いつかなくなり、運用部門は「もっと品質を高めてから出せ」「まともなマニュアルを作ってよこせ」「ちゃんとテストしてから出せ」「システムがダウンしたのは開発部門の責任だろ、なんで俺の査定が下がるんだよ!」と開発部門に迫るようになります。
一方、開発部門にも言い分はあり、「新機能をリリースすれば儲かるから早く出させろ」「今期中にリリースしないと、俺の評価査定が下がるんだ!!」「Opsが要求するテストを満たすのに1カ月かかるんですけど!!」というように、自分たちの要求を主張します。
かくして、開発と運用の業績評価指標の食い違いが、組織対立が発生させるのです。DevOpsはツールや開発体制の問題ではなく、会社の業績評価指標の問題なのです。そのため、業績評価指標を変えずにツールだけを導入するようなDevOpsは確実に失敗します。
ベクトルで分かるDevOps

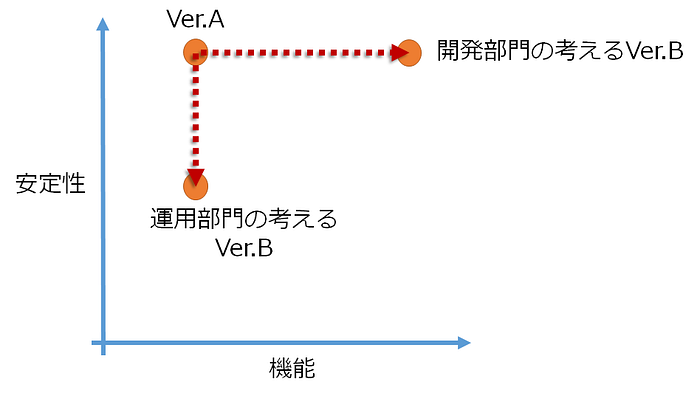
業績評価指標が直行しているので、各々の成分で見たときに対立が引き起こされる。これがDevとOpsの従来からある対立である。
この対立をどのように解決するかが、DevOpsの本質である。ツールによる解決というのは、その一部に過ぎない。
クラウドの発達による状況の変化
さて、そんなこんなで色々と問題はありつつも、状況が変わったのはここ10年ほどです。クラウドの登場により状況が変わりました。
クラウドの登場とは極論すれば「計算機資源そのものが仮想化され、計算機資源がプログラマブルになった」ということです。
つまり、Ops業務がコンピュータ制御可能になり、Devが取り扱えるようになった、ということです。
そして、仮想化や自動化に対して、様々なツール・サービスが登場しました。
AWS EC2、Docker、ServerSpec、infrataster、Chef、Puppet、Ansible、Vagrant、Capistrano、Fabric、NewRelic、Mackerel、DataDog、Zabbix、Kibana、etc,etc,….
これらのツールにより、
サーバラックに機材を積み込んで、
電源入れてOSインストールして、
必要なパッチを当てて、
ネットワーク回りの設定を書き換え、
サービスをデプロイして、
ログを画面に表示して目視確認して……
という、開発時の初期におけるOpsの手作業で行われる業務の多くをDevが取り扱えるようになりました。
もう一度言います。
「Ops業務の多くをDevが取り扱えるようになった」のです。
DevとOpsが手を取りあえばより効率的になる、という単純な話ではないのです。Devがプログラミングによって手作業を行っているOpsの仕事を奪えば、より効率的になるのです。
(Opsがプログラミングによって自らの仕事を減らすのもアリだが、プログラミングのできるOpsが少ないため、結果的にこうなることが多い)
これがDevOpsの真実なのです。
なぜ日本企業ではDevOpsがうまく回らないのか?
日本企業でDevOpsが何故難しいかというと、Opsを子会社に切り離してしまっているから、というのが私の考えです。
さてここで、NTTの組織図を見てみましょう(NTT法の話はひとまず忘れてください)。
NTTでは持ち株会社が研究部門を抱えています。
子会社の事業会社が開発を担当。
その下の孫会社の事業支援会社が実際の運用を行います。
(本当の運用は孫会社の外注だったりするが……)
なぜ運用部門を子会社に切り離してしまったのか、
ここから先は私の憶測ですが、次のような背景があると考えています。
年功序列の柔軟性を欠く賃金制度により、運用部門の低学歴低スキル労働者に対して、安い賃金を設定することができず、給与水準を適切に保つために、会社の分割が行われた。
これはNTTのみならず、他の電機メーカーも同様であると考えています。
(分かりやすい組織図があったのがNTTだけなので、NTTを例にしています)
日本企業ではスキルや職務ではなく、一般職、総合職といったくくりでしか給与テーブルの設定ができなかったため、運用部門を子会社に切り離さざるをえなかった。この状態が、ソフトウェアの時代になったにもかかわらず継続しているため、DevOpsができず、ソフトウェア開発の足を引っ張る元凶となっていると考えています。
前述のように、DevOpsはOpsの仕事をDevが奪うことですが、このような企業構造においては、「子会社に仕事を流すのも親会社の仕事」であるため、Opsの仕事を奪うことができません。
また、親会社の社員の単価は非常に高いため、付加価値が低い(とされている)コーディングや運用は禁止されてしまっていたりします。
加えて、DevOpsは、プログラミングができるDevの人がOps業務の一部を自動化できるようになる、というものであり、プログラミングのできないOpsの人がDevをできるようになる仕組みではありません。
Opsだけやってきた子会社がDevOpsなツールを導入すれば、DevOpsができる会社になるわけではありません。
大企業において、本当にDevOpsをやりたいのであれば、それはプログラミングのできない手作業Opsの人材のクビを切り、Opsの会社を潰すことを検討せねばなりません。DevOpsとは情報産業の垂直統合なのです。
この覚悟がないまま、適当なツールだけ導入してDevOpsと言ってお茶を濁すのはそろそろやめましょう。
余談:なぜビッグデータ案件はうまく回らないのか
いわゆるBigData的な改善活動がうまく回らない原因の一つに、この業務プロセスごとの子会社分割があると考えている。

顧客の活動ログが生まれる場所は実際に手を動かしている運用現場で、孫会社だったりする。それをデータサイエンティストがいる親会社の研究所まで引っ張ろうとすると、会社の壁に阻まれ、個人情報保護の壁に阻まれる。
また研究所で分析しても分析結果を元に、孫会社のオペレーションを変更するのは、やはり会社の壁に阻まれて非常に困難だ。
ハードウェアに最適化された組織は、ソフトウェアの時代に、全体最適の時代に対して、柔軟性を欠いてしまっている。
その結果、グループ全体では非常に優秀な研究者を多く抱えているのに、子会社は戦略コンサルを雇って、コンサルに現場を改善させている、ということが発生している。
DevOpsに合わせた業績評価の仕組みを構築する
さて、DevOpsが生まれた背景は次の二つです「DevとOpsの業績評価指標の食い違い」、「Ops業務の一部がプログラマブルになり、Devが取り扱えるようになった」。
つまり、DevOpsを運用するには、業績評価指標をDevOps仕様にしなくてはなりません。
一番簡単なやりかたは、各々の業績評価指標の最上位にサービスの利益を置いてしまうことです。これにより利益を重視した行動がチームに求められ、利益のためであれば、障害対応の自動化、ダウンタイムの最小化、クレームの自動チケット化などが行われていきます。
これに加え、各々がどの程度の貢献をしたかを計算し、それぞれの業績評価を行います。
これは利益が計測しやすいベンチャー企業や、サービスごとに独立した利益計算を行っている場合はうまくいきます。またベンチャー企業ではストックオプションを払い出すことで、これと同様のことを簡単に実現することができます。そのほかにも、スクラムなどはプロダクトオーナーがケツを持ち、評価に裁量を持つことで、チーム評価にすることもあります。
しかし、ある程度会社が大きくなると、個々のサービスの利益を直接計測するのが難しくなって来たり、チーム評価を推し進めた結果、どこに配属されるかという運によって給与が決定されるという、弊害があらわれてきます。
また、Devの人がOps業務の一部を担えるようになったとはいえ、全部を担うのには無理があります。餅は餅屋で分業をしたほうが専門性を活かすことができ、正しく連携できれば、比較優位の原則で生産性は改善します。
例えばGoogleではSite Reliability Engineeringという形で、インフラ、Ops部門が独立し、Devチームと協力してサービスの運用改善を進めていきます。当然ですがSREは全員がバリバリのエンジニアで、いわゆる「Ops」とは全然別モノの存在です。
そんなSREですが、オライリーからSREについての本が出ており、そこには面白い考え方が載っています。
アプリ/製品チームとSREチームは”Error Budget”を定義、共有する。これは四半期ごとに定義される、サービスレベル目標である。ユーザがサービスを使えなくなると、その時間が、このError Budgetから取り崩されていく。Budgetが残り少なくなると、リスクを伴うデプロイなどは控える。
インフラ/Ops担当は「サービスを少しでもダウンさせたら悪」となりがちだが、サービスごとにアプリ/製品チームとSREチームがError Budgetを共有することで、利害関係を一致できる。
Error Budgetの大きさはサービスごとに異なり、定義は製品チームの責任。当然Error Budgetが少ない = サービスレベルが高い = コストがかかる ので、製品チームはいたずらに高いサービスレベルを定義しない。Google Apps for WorkとYoutubeのError Budgetは異なる。Appsはサービスレベル重視であり、Youtubeは迅速で頻繁な機能追加を重視する。
Error BudgetがまさにDevとSREの共通の評価軸になります。これにより、Devはサービスを出したら終わりではなく、サービスがダウンしないように開発段階から検討するようになります。かといってBudget(予算)にすることで、サービスダウンに対する過剰品質を防ぎます。
また、How Google Worksよると「一年に一度も障害が発生していないのであれば、そのチームは難易度の高いチャレンジをしていないことだ」という話もあります(いま手元にないので引けない、あとで正しく引用する、もしかするとTeam Geekかも)。
マネージャーからしてみたら、Error Budgetが消費されていないプロジェクトは、チャレンジしていないプロジェクト、もしくは、品質過剰になっているプロジェクトだという認識もでき、アラートの兆候にもなります。
また余談ですが、同書は最近無料公開されたらしいので、英語の勉強がてらに読んでみるのもいいんじゃないでしょうか。翻訳されたら即買うので、オライリージャパンの方はぜひとも翻訳して頂けますとうれしいです。
追記1:現在翻訳中だそうです。やったー
追記2:でたよー
まとめ
- DevとOpsは、要求するスキル・業績評価指標が異なるため、組織分割される。
- DevとOpsは、業績評価指標が異なるために、合理的な行動を行うことで対立が発生する。
- DevOpsとは、Ops業務がプログラマブルになったため、従来Ops業務とされていたものをDevチーム内に取り込む活動。
- DevOps業務を業績評価指標に組み込まねば、DevOpsを運用することはできない。GoogleはError Budgetという形で評価。
- DevOps業務を業績評価指標に組み込むと、効率化のためにエンジニアがより活発にOpsを自動化し、改善が行われていく。
余談:ローテーション人事の闇
大企業では正社員の育成のためにローテーション人事が行われています。様々な部門を異動することで、マルチスキルの人材を育成し、問題解決能力や、部門を跨いだ人脈の構築、リーダーシップの獲得を目的として行われています。
しかし、これが時として、DevOpsの体制構築の妨げとして働きます。
以下は実際に私が言われた言葉です。
「正社員は2年で異動してしまう、だからプログラミングを覚えても意味がない。だれが引継ぎをするんだ」
「プログラミングは下請けにやらせろ。下請けの使い方は異動先でも使える」
「そんなことより、仕様書の書き方を覚えろ、どこへ異動しても使える」
というわけで、ローテーション人事に現場が効率的に対応した結果、知識だけでしか仕事を知らず、手を動かせず、ベンダーを呼びつけることしかできないオジサンが出来上がるわけでした。
そりゃDevOpsとか無理っすよー。ローテーション人事のせいで社内にコード書ける人材が育たないんだから。
